
Illustrated Guide to Transformer
A component by component breakdown analysis.
The Transformer model is the evolution of the encoder-decoder architecture, proposed in the paper Attention is All You Need. While encoder-decoder architecture has been relying on recurrent neural networks (RNNs) to extract sequential information, the Transformer doesn’t use RNN. Transformer based models have primarily replaced LSTM, and it has been proved to be superior in quality for many sequence-to-sequence problems.
Transformer relies entirely on Attention mechanisms to boost its speed by being parallelizable. It has produced state-of-the-art performance in machine translation. Besides significant improvements in language translation, it has provided a new architecture to solve many other tasks, such as text summarization, image captioning, and speech recognition.
Before the Transformer model, recurrent neural networks (RNNs) have been the go-to method for sequential data, where the input data has a defined order. RNNs work like a feed-forward neural network that unrolls the input over its sequence, one after another.
]](/assets/img/posts/illustrated-guide-transformer-02.jpg)
This process of unrolling each symbol in the input is done by the Encoder, whose objective is to extract data from the sequential input and encode it into a vector, a representation of the input.
Examples of sequential input data are words (or characters) in a product review where the RNN will extract each word sequentially, forming a sentence representation. This representation will be used as a feature for the classifier to output a fixed-length vector, such as a sentiment label indicating positive/negative, or on a 5-point scale.
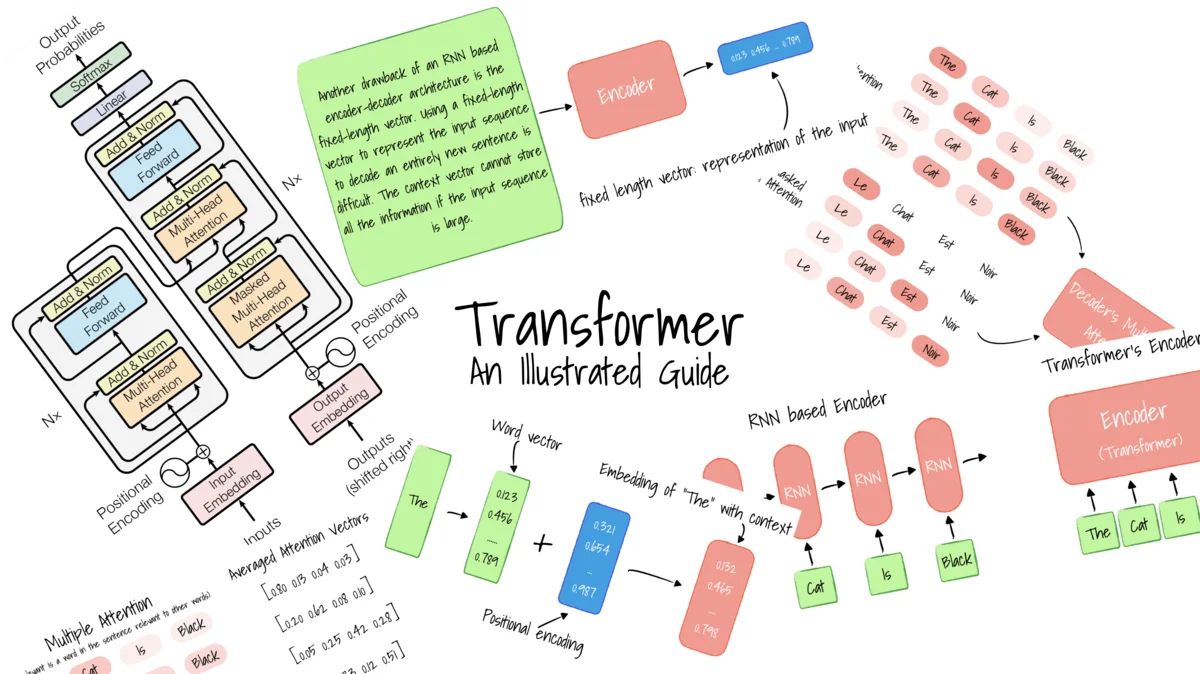
In machine translation and image captioning, instead of a classifier that outputs a fixed-length vector, we can replace it with a Decoder. Like the Encoder that consumes each symbol in the input individually, the Decoder produces each output symbol over several time steps.
For example, in machine translation, the input is an English sentence, and the output is the French translation. The Encoder will unroll each word in sequence and forms a fixed-length vector representation of the input English sentence. Then, the Decode will take the fixed-length vector representation as input, and produce each French word one after another, forming the translated English sentence.
Problem with RNN based Encoder-Decoder
However, RNN models have some problems, they are slow to train, and they can’t deal with long sequences.
The input data needs to be processed sequentially one after the other. Such a recurrent process does not make use of modern graphics processing units (GPUs), which were designed for parallel computation. RNNs are so slow that truncated backpropagation was introduced to limit the number of timesteps in the backward pass–estimating gradients to update the weights rather than backpropagation fully. Even with truncated backpropagation, RNNs are still slow to train.
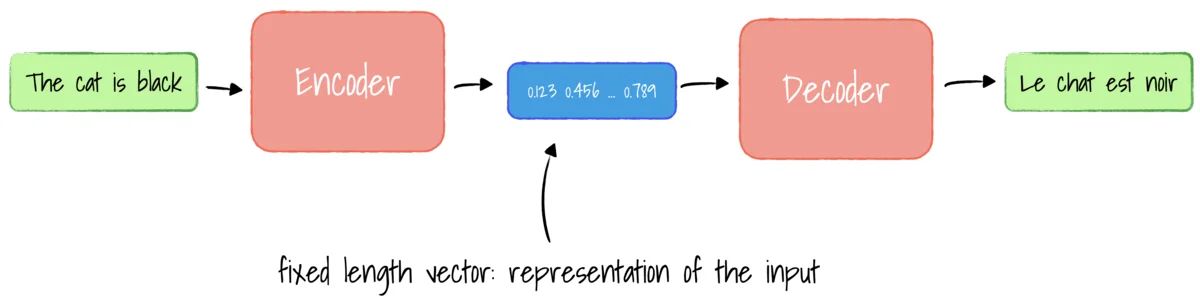
Secondly, RNNs also can’t deal with long sequences very well as we get vanishing and exploding gradients if the input sequence is too long. Generally, you will see NaN (Not a Number) in the loss during the training process. These are also known as the long-term dependency problems in RNNs.
In 1997, Hochreiter & Schmidhuber introduced the Long Short Term Memory (LSTM) networks, which are explicitly designed to avoid long-term dependency problems. Each LSTM cell allows past information to skip all the processing of the current cell and move to the next cell; this allows the memory to be retained longer and will enable data to flow along with it unchanged. LSTM consists of an input gate that decides what new information to be stored and a forget gate that determines what information to remove.
]](/assets/img/posts/illustrated-guide-transformer-05.jpg)
Certainly, LSTMs have improved memory, able to deal with longer sequences than RNNs. However, LSTM networks are even slower as they are more complex.
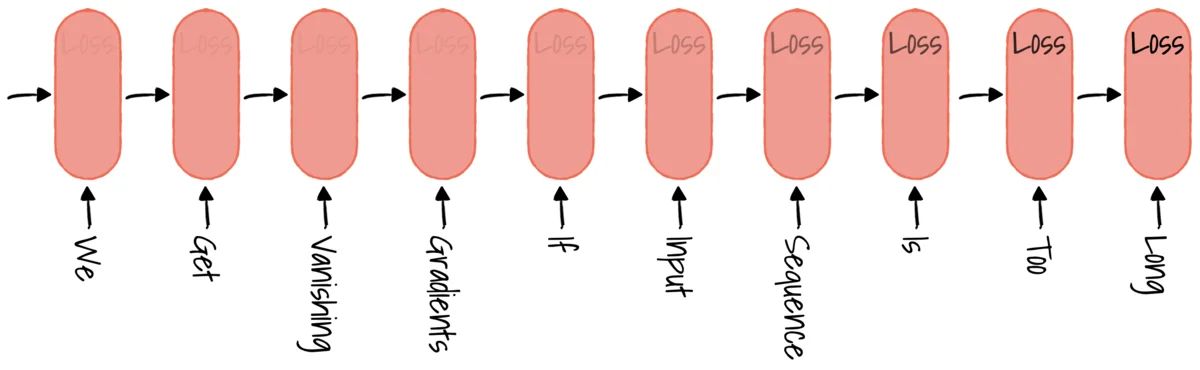
Another drawback of an RNN based encoder-decoder architecture is the fixed-length vector. Using a fixed-length vector to represent the input sequence to decode an entirely new sentence is difficult. The context vector cannot store all the information if the input sequence is large. Furthermore, it is challenging to differentiate sentences with similar words but with different meanings.
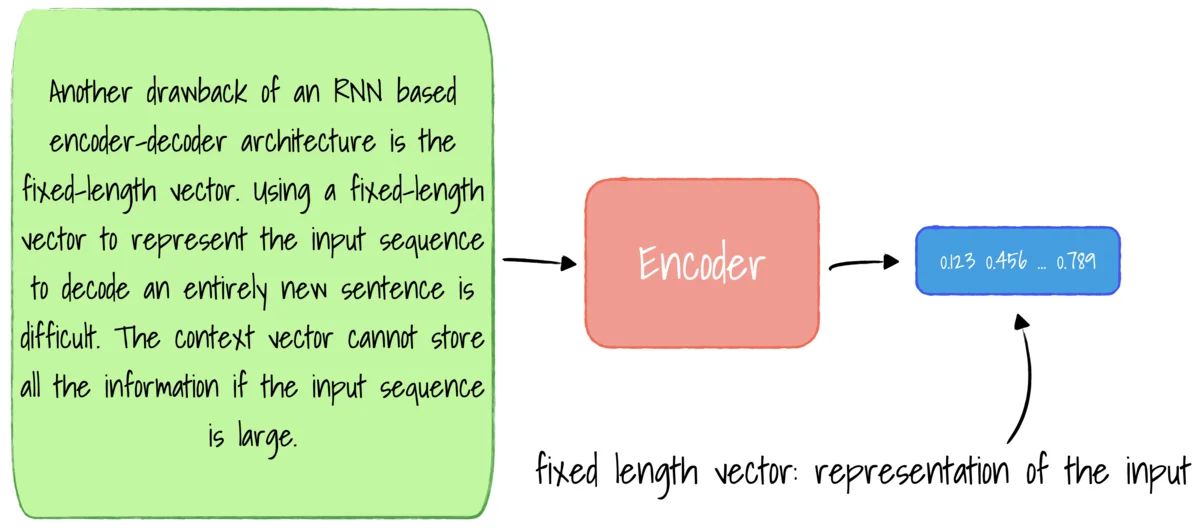
Using a fixed-length vector to represent the input sequence.
Imagine this, selects a paragraph above (input) and memorize it (fixed-length vector). Then, translate that entire paragraph (output) without referring to it. It is difficult, and that is not how we do it. Instead, when we translate a sentence from one language to another, we look at the sentence part by part, by paying attention to a particular phrase of the sentence each time.
Bahdanau proposed a method to search for parts of a source sentence relevant to predicting a target word in an encoder-decoder model. This is the beauty of the Attention mechanism; we can translate comparatively longer sentences without affecting its performance using Attention. For example, translating to “noir” (which means “black” in French), the Attention mechanism will focus on the word “black” and possibly “cat,” ignoring other words in the sentence.
]](/assets/img/posts/illustrated-guide-transformer-07.jpg)
The attention mechanism has increased encoder-decoder networks’ performance, but the bottleneck in speed is still due to RNN having to process word by word sequentially. Can we remove RNN for sequential data?
How can we use parallelization for sequential data?
Yes! Attention is all you need. The Transformer architecture was introduced in 2017. Like the encoder-decoder architectures, where input sequences are fed into the Encoder, and Decoder will predict each word after another. The Transformer improves its time complexity and performance by eliminating RNN and utilizing the attention mechanism.
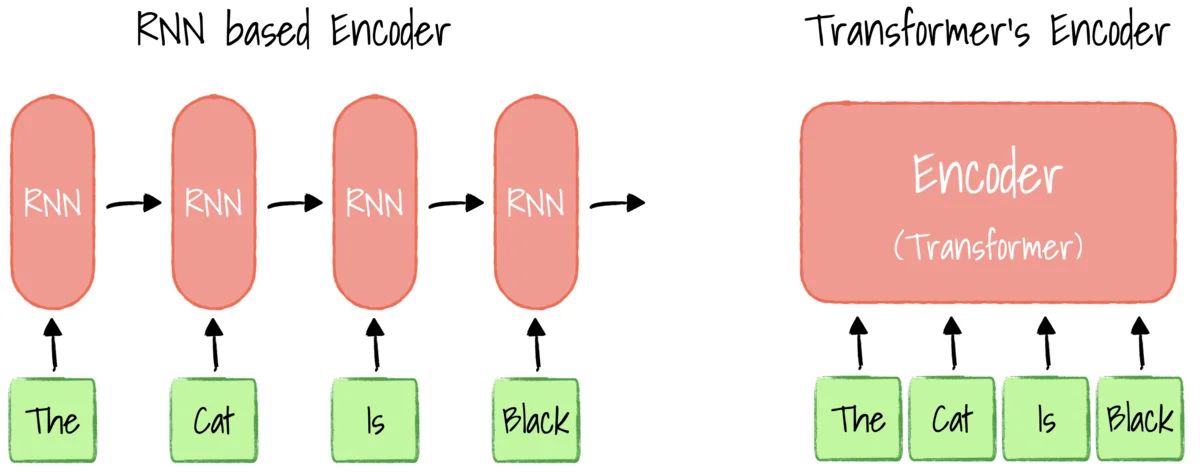
Considering translating a sentence from English to French. In RNN, each hidden state has dependencies on the previous words’ hidden state. Thus the embeddings of the current step are generated one time step at a time. With Transformer, there is no concept of the time step; the input sequence can be passed into the Encoder in parallel.
Transformer
Let’s assume we are training a model that translates the English sentence to French. The Transformer architecture has two parts, the Encoder (left) and the Decoder (right). Let’s examine the Transformer architecture.
]](/assets/img/posts/illustrated-guide-transformer-09.jpg)
In the Encoder, it inputs an English sentence, and the output will be a set of encoded vectors for every word. Each word in the input English sentence is converted into an embedding to represent meaning. Then we add a positional vector to add the context of the word in the sentence. These word vectors are fed into Encoder attention block, which computes the attention vectors for every word. These attention vectors are passed in through a feed-forward network in parallel, and the output will be a set of encoded vectors for every word.
The Decoder receives input of the French word(s) and attention vectors of the entire English sentence, to generate the next French word. It encodes each word’s meaning with the embedding layer. Then positional vectors are added to represent the context of the word in the sentence. These word vectors are fed into the first attention block, the masked attention block. The masked attention block computes the Attention vectors for current and prior words. Attention vectors from the Encoder and Decoder are fed into the next attention block, which generates attention mapping vectors for every English and French word. These vectors are passed into the feed-forward layer linear layer and the softmax layer to predict the next French word. We repeat this process to generate the next word until the “end of sentence” token is generated.
This is the high-level details of how Transformer works. Let’s dive deeper and examine each component.
Embeddings
Since computers don’t understand words—its meanings and its relationship between words like we do; we need to replace the words with vectors. Word vectors (or embeddings) allow every word to be mapped in a high dimensional embedding space, where words with similar meanings are closer to each other.
Even though we can reference and represent each word’s meaning with a vector, the true meaning of a word relies on the context in the sentence, as the same word in different sentences may have different meanings. As RNN was designed to capture sequence information, how the Transformer handles word order without RNN? We need positional encoders.
Positional encoders
The positional encoders receive inputs from the input embeddings layer and apply relative positional information. This layer outputs word vectors with positional information; that is the word’s meaning and its context in the sentence.
Consider the following sentences, “The dog bit Johnny” and “Johnny bit the dog.” Without context information, both sentences would have almost identical embeddings. But we know this is not true, definitely not true for Johnny.
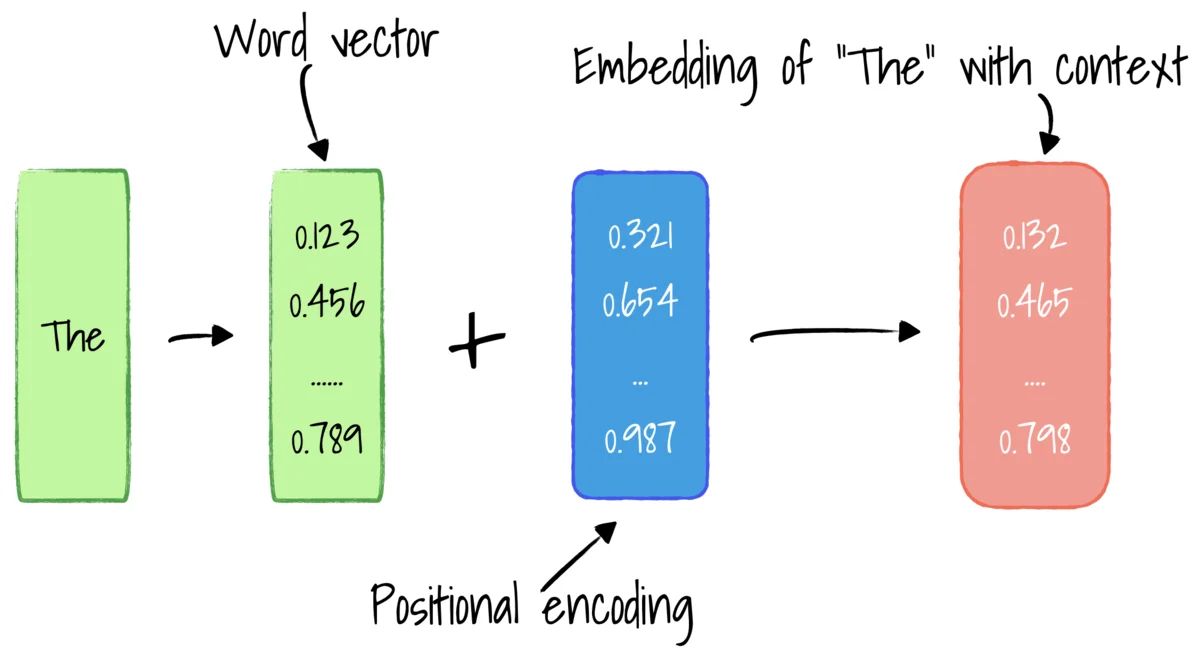
The authors proposed using multiple sine and cosine functions to generate positional vectors. This way, we can use this positional Encoder for sentences of any length. The frequency and offset of the wave are different for each dimension, representing each position, with values between -1 and 1.
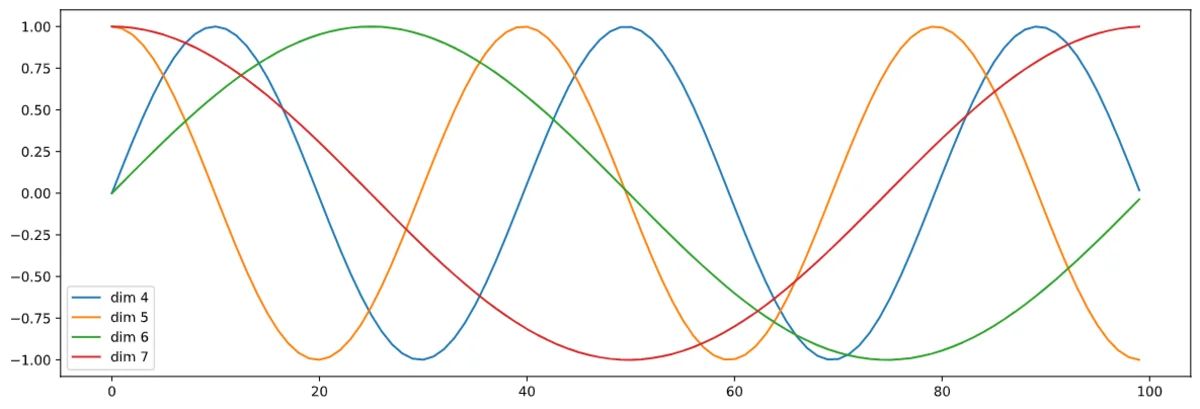
This binary encoding method also allows us to determine if two words are near each other. For example, by referencing the low-frequency sine wave, if one word has “high” while another is “low,” we know that they are further apart, one located at the beginning, another at the end.
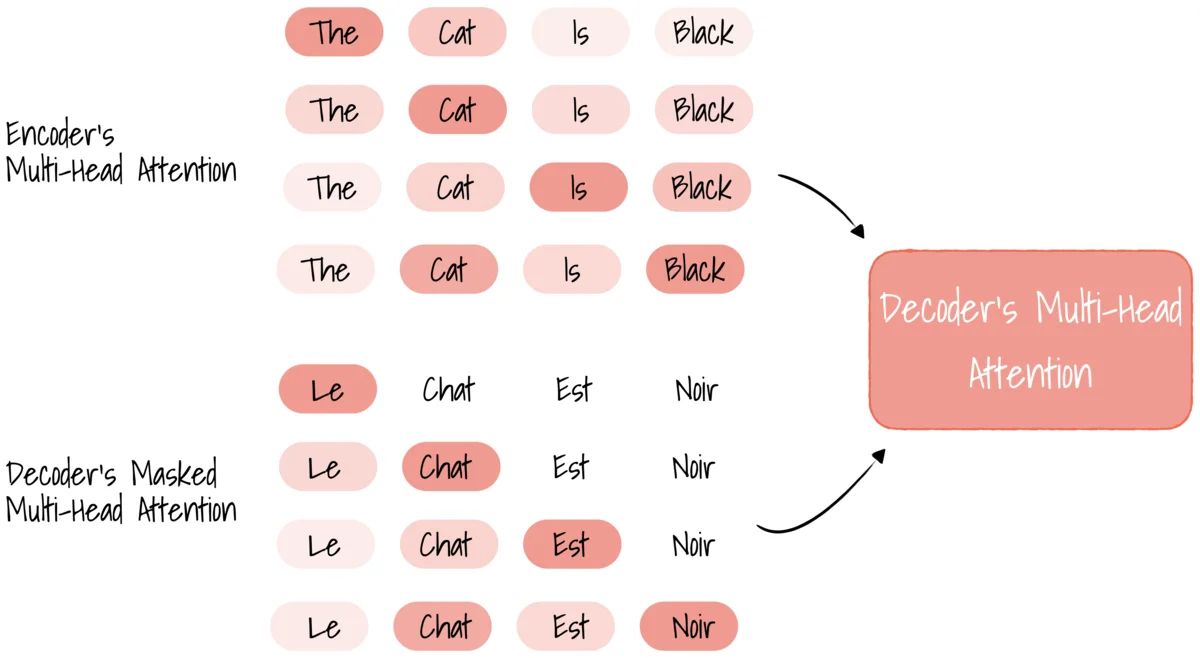
Encoder’s Multi-Head Attention
The key purpose of Attention is answering, “what part of the input should I focus on?” If we’re encoding an English sentence, the question we want to answer is, “how relevant is a word in the English sentence relevant to other words in the same sentence?” This is represented in the Attention vector. For every word, we can have an Attention vector generated that captures contextual relationships between words in a sentence. For example, for the word “black,” the Attention mechanism focus on “black” and “cat.”
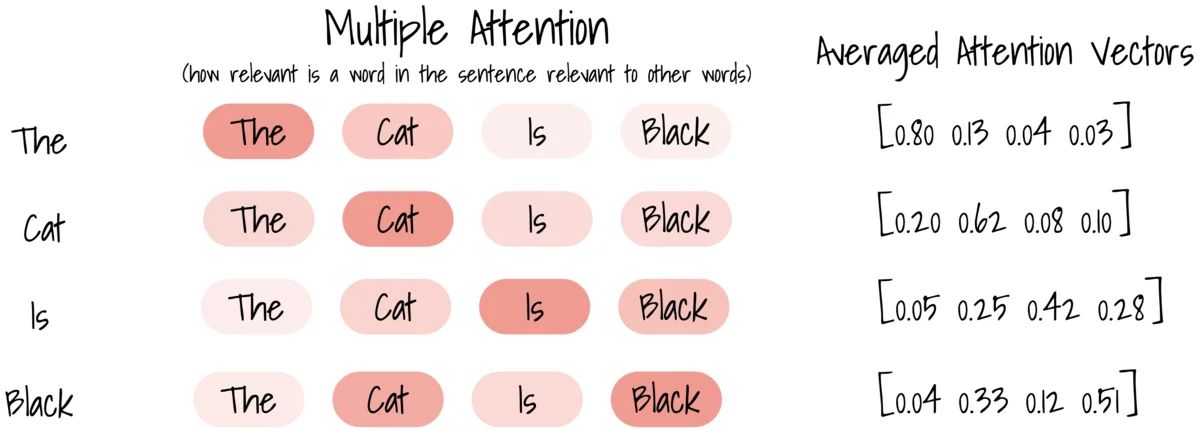
As we are interested in the interactions between different words, the Attention vector for each word may weight itself too highly. As such, we need a way to normalize the vector. The Attention block accepts inputs V, K, and Q–these are abstract vectors that extract different components of an input word. We use these to compute the Attention vectors for every word.
Why is it called “Multi-Head Attention”? That is because we are using multiple Attention vectors per word and take a weighted average to compute the final Attention vector for every word.
Encoder’s feed-forward
As the multi-head Attention block output multiple Attention vectors, we need to convert these vectors into a single Attention vector for every word.
This feed-forward layer receives Attention vectors from the Multi-Head Attention. We apply normalization to transform it into a single Attention vector. Thus we get a single vector is digestible by the next encoder block or decoder block. In the paper, the author stacks six encoder blocks before output to the decoder block.
Decoder’s output embedding and positional encoders
Since we’re translating from English to French, we input French word(s) to the Decoder. We replace the words with word embeddings, and then we add the positional vector to get the notion of context of the word in a sentence. We can feed these vectors that contain the word’s meaning and its context in the sentence into the Decoder block.
Decoder’s Masked Multi-Head Attention
Similar to the Multi-Head Attention in the Encoder block. The Attention block generates Attention vectors for every word in the French sentence to represent how much each word is related to every word in the same output sentence.
Unlike the Attention block in the Encoder that receiving every word in the English sentence, only the previous words of the French sentence are fed into this Decoder’s Attention block. Thus, we mask the words appearing later using a vector and representing it in zeros, so the attention network can’t use them while performing matrix operations.

Decoder’s Multi-Head Attention
This Attention block acts as the Encoder-Decoder, which receives vectors from the Encoder’s multi-head Attention and Decoder’s Masked Multi-Head Attention. This Attention block will determine how related each word vector is with respect to each other, and this is where the mapping from English to French word happens. The output of this block is Attention vectors for every word in English and French sentences, where each vector representing the relationships with other words in both languages.
Decoder’s feed-forward
Like the Encoder’s feed-forward layer, this layer normalized each word consisting of multiple vectors into a single Attention vector for the next decoder block or a linear layer. In the paper, the author stacks six decoder blocks before output to the linear layer.
Decoder’s linear layer and softmax
As the purpose of the Decoder is to predict the following word, the output size of this feed-forward layer is the number of French words in the vocabulary. Softmax transforms the output into a probability distribution, which outputs a word corresponding to the highest probability of the next word.
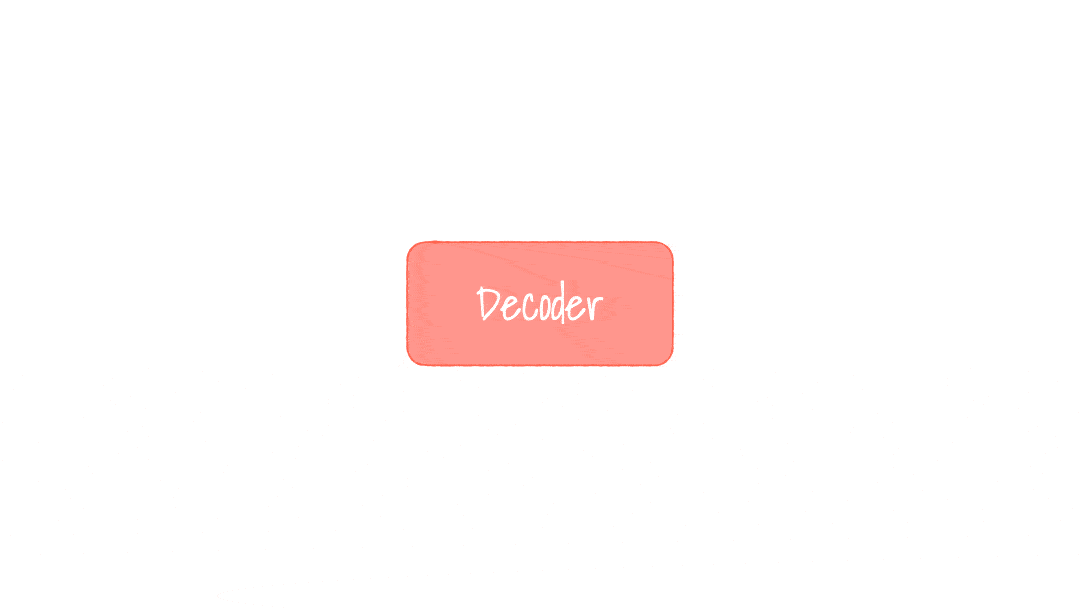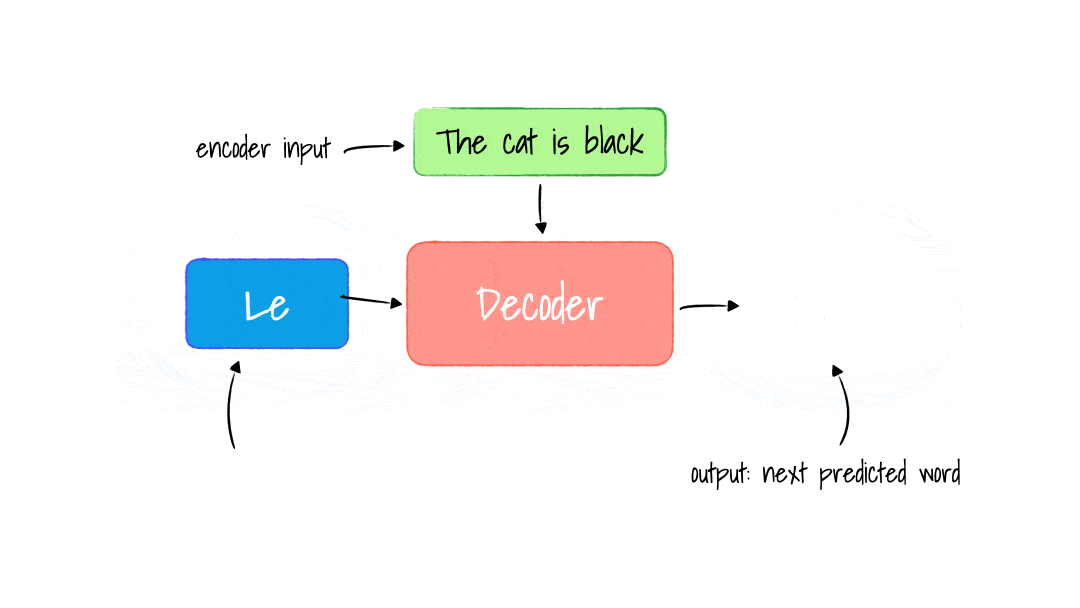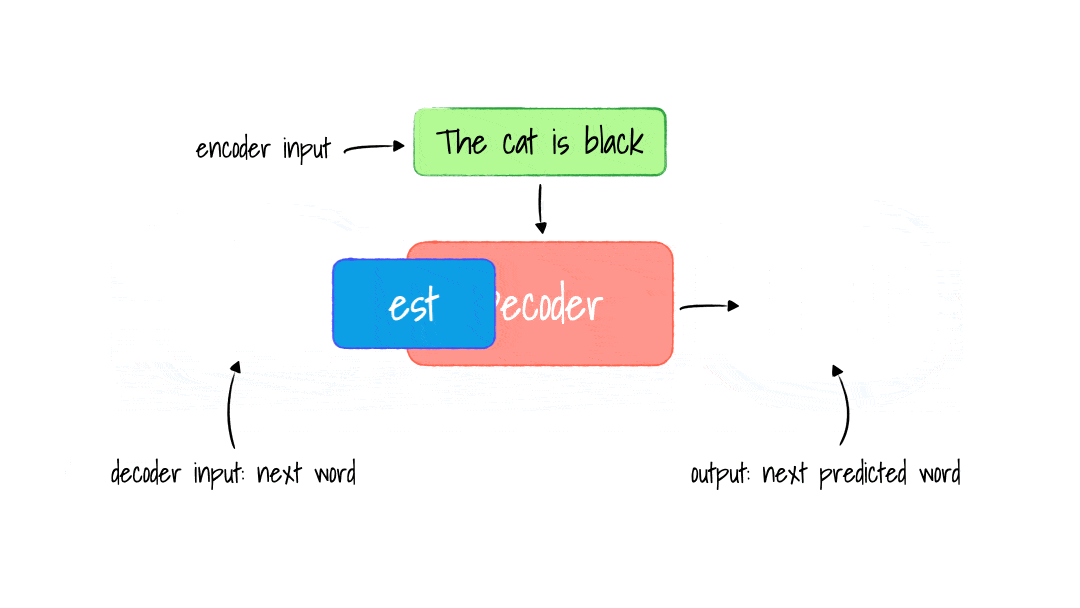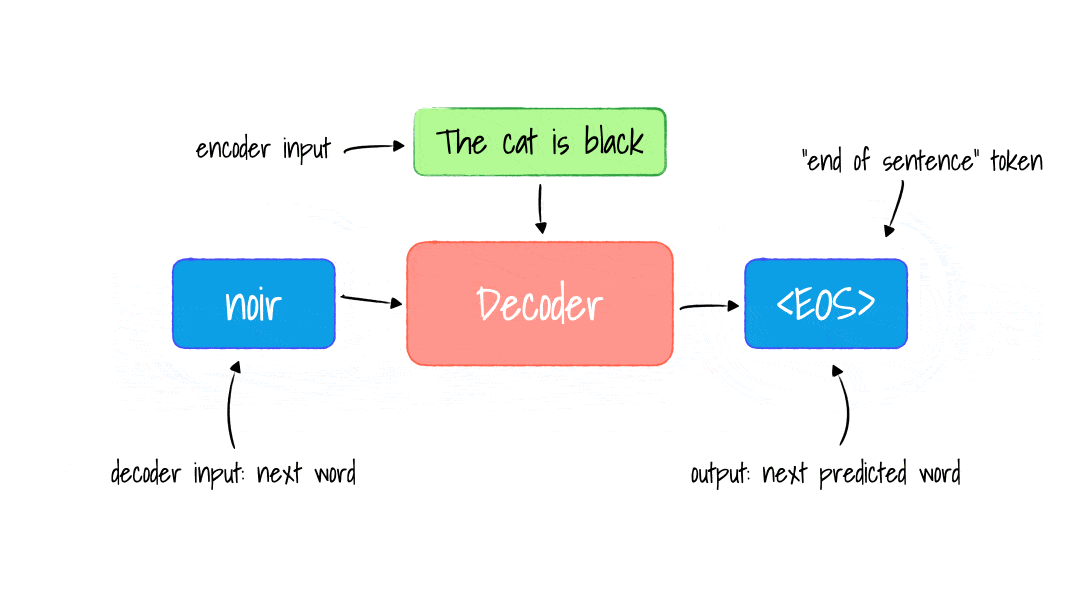
For each word generated, we repeat this process, including the French word, and used it to generate the next until the end of sentence tokens generated.
Get started
Both TensorFlow and PyTorch has a step-by-step tutorial that can help you understand and train a sequence-to-sequence model with Transformer. If you need something fast for production, probably the most popular option is by Hugging Face.



