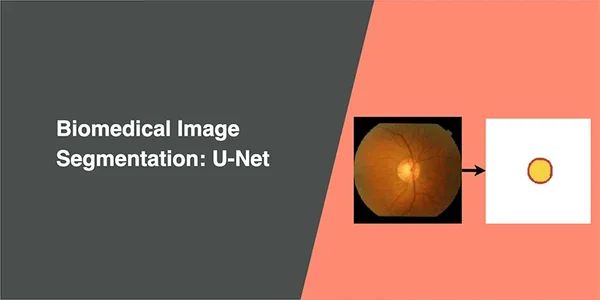
Biomedical Image Segmentation - Attention U-Net
Improving model sensitivity and accuracy by attaching attention gates on top of the standard U-Net

Medical image segmentation has been actively studied to automate clinical analysis. Deep learning models generally require a large amount of data, but acquiring medical images is tedious and error-prone.
Attention U-Net aims to automatically learn to focus on target structures of varying shapes and sizes; thus, the name of the paper “learning where to look for the Pancreas” by Oktay et al..
Related works before Attention U-Net
U-Net
U-Nets are commonly used for image segmentation tasks because of its performance and efficient use of GPU memory. It aims to achieve high precision that is reliable for clinical usage with fewer training samples because acquiring annotated medical images can be resource-intensive. Read more about U-Net.
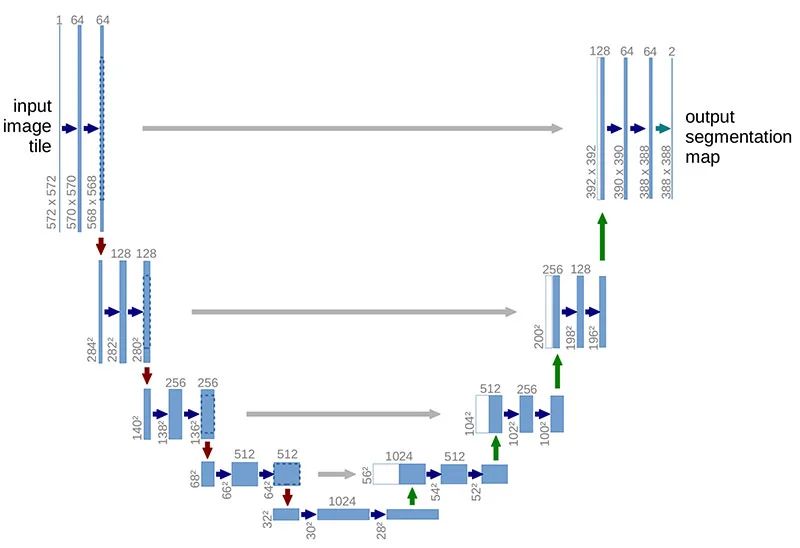
Despite U-Net excellent representation capability, it relies on multi-stage cascaded convolutional neural networks to work. These cascaded frameworks extract the region of interests and make dense predictions. This approach leads to excessive and redundant use of computational resources as it repeatedly extracting low-level features.
Attention gates
“Need to pay attention” by Jetley et al. introduced end-to-end-trainable attention module. Attention gates are commonly used in natural image analysis and natural language processing.
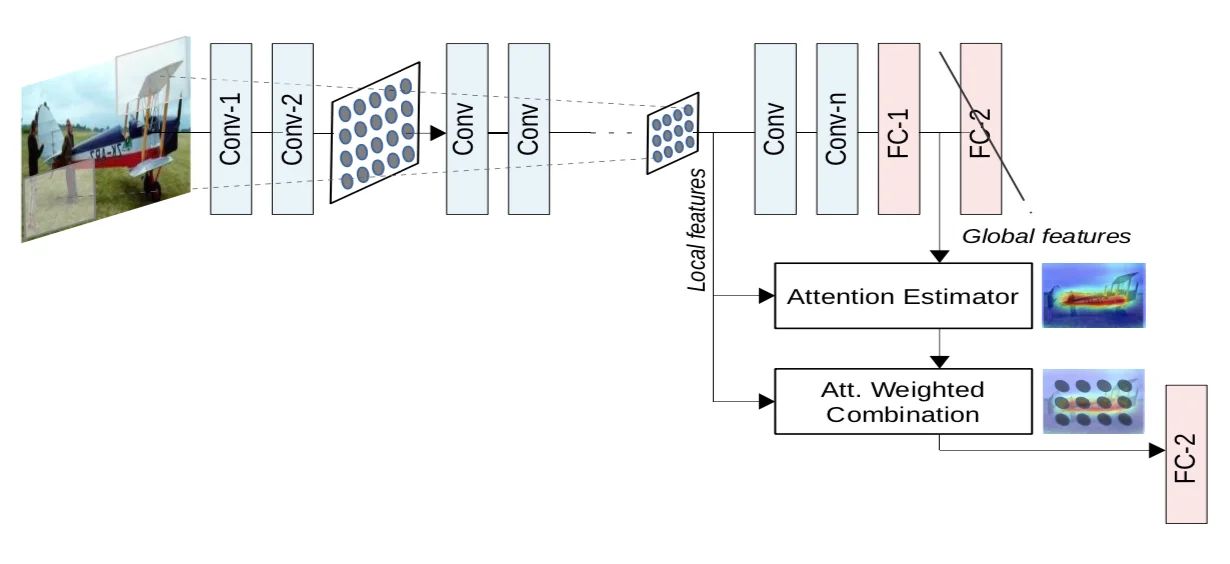
Attention is used to perform class-specific pooling, which results in a more accurate and robust image classification performance. These attention maps can amplify the relevant regions, thus demonstrating superior generalisation over several benchmark datasets.
Soft and hard attention
How hard attention function works is by use of an image region by iterative region proposal and cropping. But this is often non-differentiable and relies on reinforcement learning (a sampling-based technique called REINFORCE) for parameter updates which result in optimising these models more difficult.
On the other hand, soft attention is probabilistic and utilises standard back-propagation without need for Monte Carlo sampling. The soft-attention method of Seo et al. demonstrates improvements by implementing non-uniform, non-rigid attention maps which are better suited to natural object shapes seen in real images.
What is new in Attention U-Net?
Attention gates
To improve segmentation performance, Khened et al. and Roth et al. relied on additional preceding object localisation models to separate localisation and subsequent segmentation steps. This can be achieved by integrating attention gates on top of U-Net architecture, without training additional models.
As a result, attention gates incorporated into U-Net can improve model sensitivity and accuracy to foreground pixels without requiring significant computation overhead. Attention gates can progressively suppress features responses in irrelevant background regions.
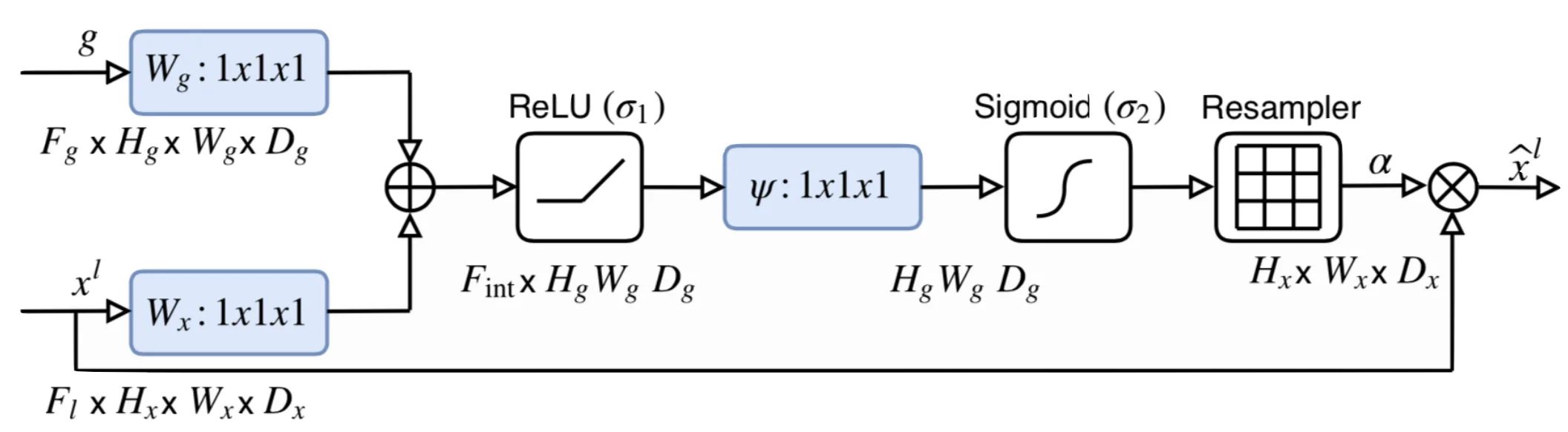
Attention gates are implemented before concatenation operation to merge only relevant activations. Gradients originating from background regions are down-weighted during the backward pass. This allows model parameters in prior layers to be updated based on spatial regions that are relevant to a given task.
Grid-based gating
To further improve the attention mechanism, Oktay et al. proposed a grid-attention mechanism. By implementing grid-based gating, the gating signal is not a single global vector for all image pixels, but a grid signal conditioned to image spatial information. The gating signal for each skip connection aggregates image features from multiple imaging scales.
By using grid-based gating, this allows attention coefficients to be more specific to local regions as it increases the grid-resolution of the query signal. This achieves better performance compared to gating based on a global feature vector.
Soft-attention technique
Additive soft attention is used in the sentence to sentence translation (Bahdanau et al., Shen et al.) and in image classification (Jetley et al., Wang et al.). Although this is computationally more expensive, Luong et al. have shown that soft-attention can achieve higher accuracy than multiplicative attention.
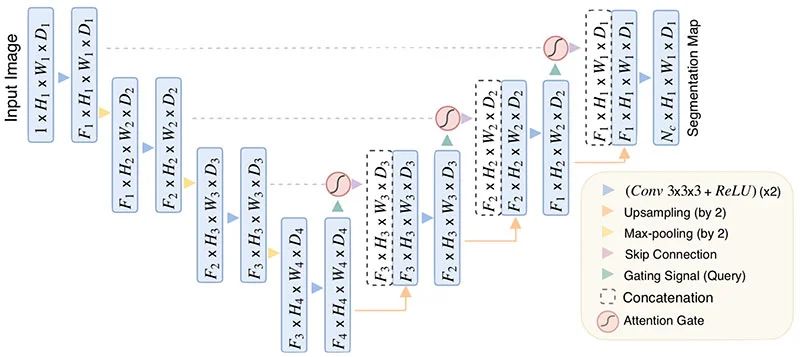
Architecture
Below is an illustration of Attention U-Net.
My experiment on Attention U-Net
I will be using the Drishti-GS Dataset, which contains 101 retina images, and annotated mask of the optical disc and optical cup. 50 images will are for training and 51 for validation.
The experiment setup and the metrics used will be the same as the U-Net.
The model completed training in 13 minutes; each epoch took approximately 15 seconds.
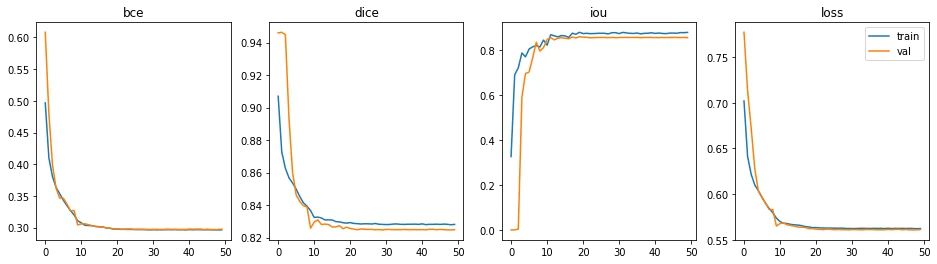
The metrics between several U-Net models for comparison, as shown below.
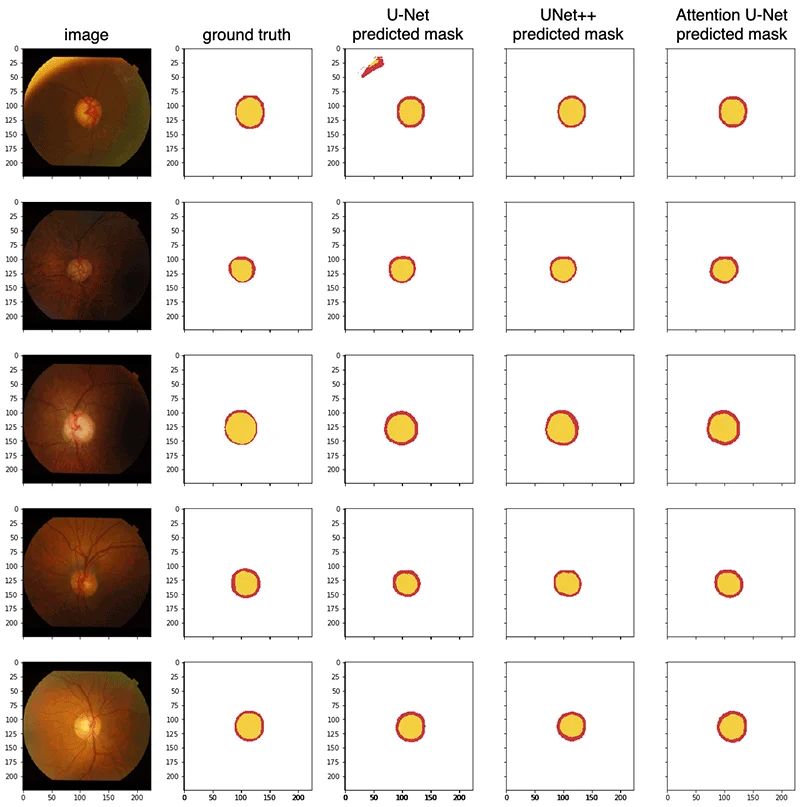
The test began with the model processing a few unseen samples, to predict optical disc (red) and optical cup (yellow). Here are the test results for Attention U-Net, UNet++ and U-Net for comparison.
Conclusion
Attention U-Net aims to increase segmentation accuracy further and to work with fewer training samples, by attaching attention gates on top of the standard U-Net.
Attention U-Net eliminates the necessity of an external object localisation model which some segmentation architecture needs, thus improving the model sensitivity and accuracy to foreground pixels without significant computation overhead.
Attention U-Net also incorporate grid-based gating, which allows attention coefficients to be more specific to local regions.
Here is the PyTorch code of Attention U-Net architecture: