
Striking a Balance between Exploring and Exploiting
The dilemma of exploration and exploitation in reinforcement learning

The exploration-exploitation dilemma is faced by our agents while learning to play the game tic-tac-toe. This dilemma is a fundamental problem in reinforcement learning as well as in real life which we frequently face when choosing between options, would you rather:
- pick something you are familiar in order to maximise the chance of getting what you wanted
- or pick something you have not tried and possibly learning more, which may (or may not) result in you making better decisions in future
This trade-off will affect either you earn your reward sooner or you learn about the environment first then earn your rewards later.
Intuition
Let’s say you relocated to a new town, and you are figuring out which way to travel from your office to your new home. You did a quick search and found that there are a few ways:
- take subway line A followed line B
- take subway line A followed by bus 123
- walk to subway line C followed by line B
Initially, you won’t have any idea which is the best way, but you trusted technology, so picked option 1 as it has the shortest duration. You managed to reach home on day 1, so you decided that option 1 will be your route home. You continue to exploit what you know that worked and travel via option 1.
Maybe one day, you decided to explore, thinking there might be a better way to go home from your office, so you decided to try option 2. The outcomes could be either you manage to get home in a shorter time or it cost you more time (and maybe fare as well). After trying option 2, indeed it took longer than option 1. Maybe because during peak hours, the traffic is bad for bus 123. So you decided that option 2 isn’t good. But does that mean that you will never try option 2 ever again? It might be a better option during off-peak hours.
What if option 3 is actually the optimal way home, but decided to never explore again and stick with option 1? Then you will never able to realise that option 3 is better than option 1.
Striking a Balance
Learning to make these choices is part of reinforcement learning. This means that sometimes you purposely have to decide not to choose the action that you think will be the most rewarding in order to gain new information, but sometimes ended up making some bad decisions in the process of exploration. But at the same time, you want to maximise your reward, by exploiting what you know worked best.
So how do we strike a balance between sufficiently exploring the unknowns and exploiting the optimal action?
- sufficient initial exploration such that the best options may be identified
- exploit the optimal option in order to maximise the total reward
- continuing to set aside a small probability to experiment with sub-optimal and unexplored options, in case they provide better returns in the future
- if those experiment options turn out to be doing well, the algorithm must update and begin selecting this option
Epsilon Greedy
In reinforcement learning, we can decide how much exploration to be done. This is the epsilon-greedy parameter which ranges from 0 to 1, it is the probability of exploration, typically between 5 to 10%. If we set 0.1 epsilon-greedy, the algorithm will explore random alternatives 10% of the time and exploit the best options 90% of the time.
Evaluate Different Epsilon Greedy
I’ve created a tic-tac-toe game where agents can learn the game by playing against each other. First, let me introduce you to our agents, they are agent X and agent O. Agent X always goes first and actually has the advantage to win more often than agent O.
In order to figure out the most suitable epsilon-greedy value for each agent for this game, I will test different epsilon-greedy value. First, initialise agent X with epsilon-greedy of 0.01, means there is 1% probability agent X will choose to explore instead of exploiting. Then, agents will play against each other for 10,000 games, and I will record the number of times agent X wins. After 10,000 games, I will increase the epsilon-greedy value to 0.02 and agents will play another 10,000 games.
Agent X (eps increment) vs Agent O (eps 0.05), the results are as follows:
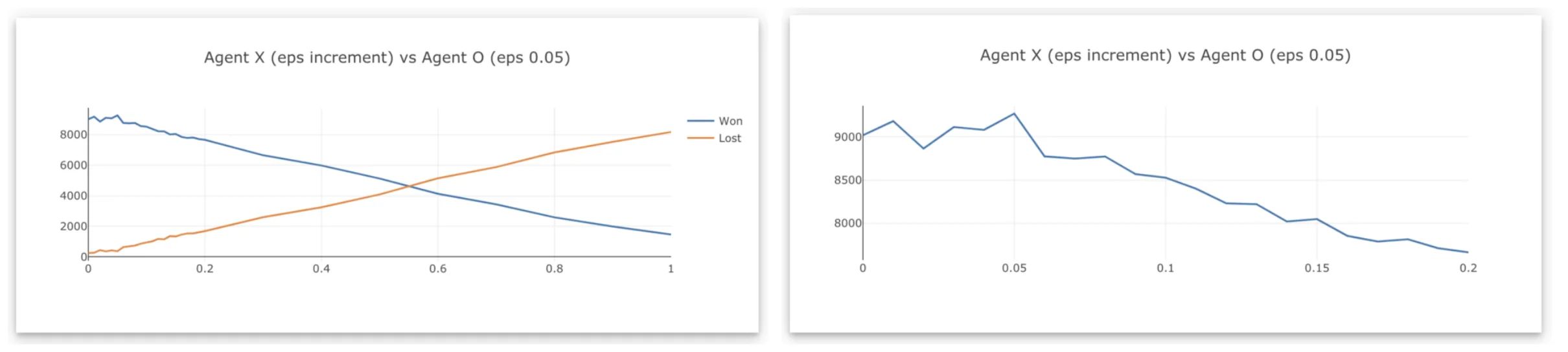
The blue line is the number of times agent X won against agent O. The winning rate decreases as the epsilon-greedy value increases and peaked at winning 9268 games at the epsilon-greedy value of 0.05 (agent X explores 5% of the time). Agent O begin to win more games as agent X explores more than 50% of the time.
Let us try something, agent O challenging agent X with an optimal 5% epsilon greedy, let’s see how agent O performs on different epsilon-greedy value.
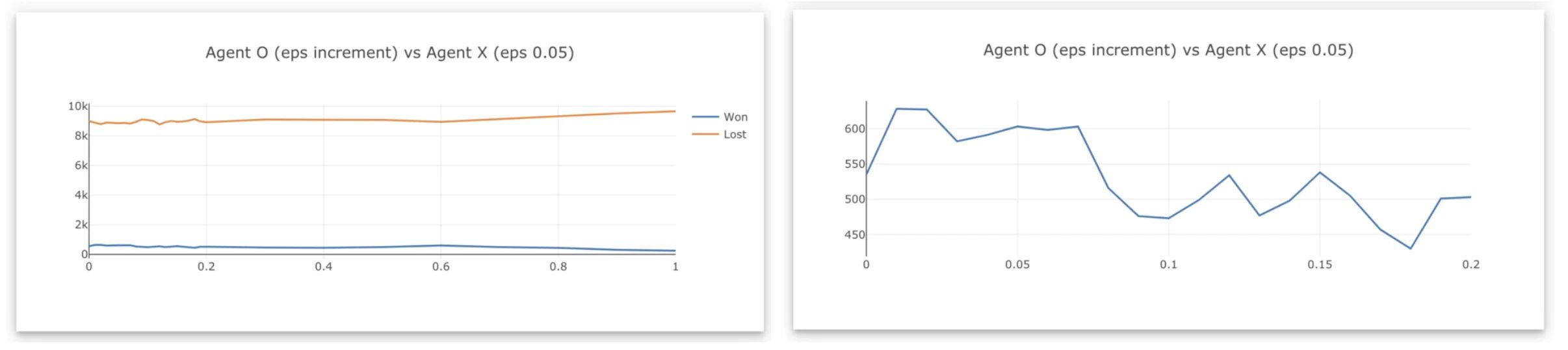
Given agent X has optimal epsilon greedy and advantage to start first in the game, agent O lost most of the games before it is able to learn the game.
Let’s tweak epsilon greedy of agent X to 100%, where agent X will be playing random actions all the time.
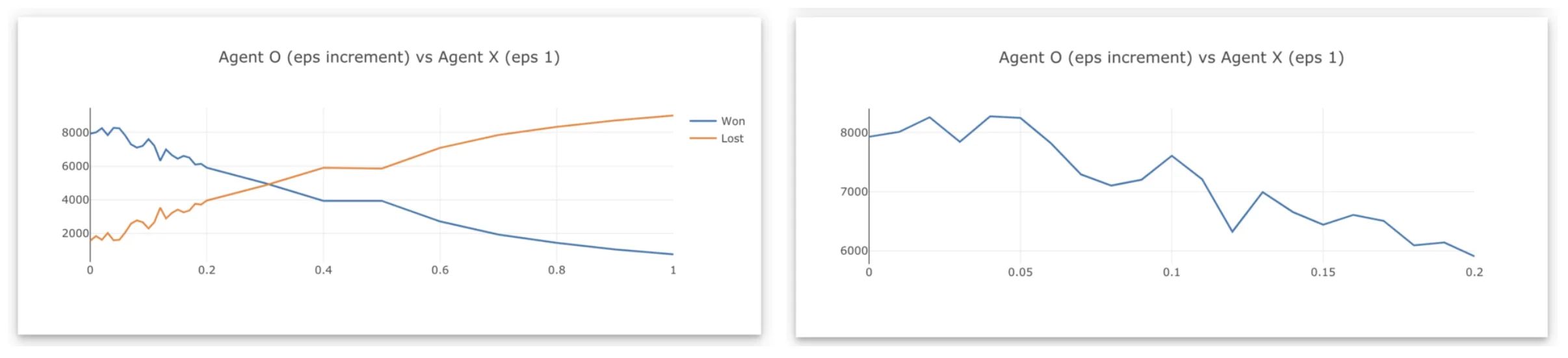
Agent O is able to learn the game and win against agent X, peaking at 4% epsilon greedy and begin losing at 30%.
Lastly
Explore the online demo and challenge our agent in a game of tic-tac-toe.
Just want to end with this picture.


